
Heiko Petersen, Patrick Meade Vargas, ABB Process Automation Mannheim, Germany, heiko.petersen@
de.abb.com, patrick.meade@
de.abb.com
Ruomu Tan, ABB Corporate Research Process Automation, Ladenburg, Germany, ruomu.tan@de.abb.com
Ein gutes Beispiel ist die PlantInsight-Plattform von ABB →01. Sie ermöglicht die Ausführung verschiedener Algorithmen des maschinellen Lernens (ML) zur Erkennung, Segmentierung und Vorhersage bestimmter Muster in großen Mengen von Prozessdaten. Dies wiederum erlaubt die Implementierung von KI-basierten Optimierungslösungen, die dabei helfen, Schadstoffe zu mindern, die Lebensdauer von Betriebsmitteln zu verlängern und Produktionskosten zu senken.

Künstliche Intelligenz (KI) scheint heutzutage omnipräsent zu sein. Das Thema ist in aller Munde, Buchläden sind voll von Literatur darüber, und nur wenige Anwendungen scheinen ohne sie auszukommen. Doch angesichts des ganzen Hypes stellt sich die Frage, warum KI in der Prozessindustrie noch immer selten Anwendung findet. Oder wird sie bereits verwendet, aber nur nicht als solche erkannt?
Allgemein gilt ein System als KI-gestützt, wenn es in der Lage ist, typisch menschliche Aufgaben zu übernehmen, wie etwa das optische Erfassen, Treffen von Entscheidungen, Erkennen von Sprache oder Übersetzen. Tatsächlich können KI-gestützte Systeme dem Menschen bei bestimmten Aufgaben sogar überlegen sein. Dazu gehört das Lösen von numerischen Problemen, das Erkennen von Mustern und das Extrahieren von Informationen aus einer großen Zahl von Quellen. Trotzdem stecken solche Systeme noch immer in den Kinderschuhen, wenn es ums Abstrahieren oder um das kreative Umsetzen von Informationen in eloquente Texte geht – ganz zu schweigen von solchen Dingen wie sozialer Interaktion, Bewusstsein oder Selbsterkenntnis, die für den Menschen allesamt Routine, aber für Maschinen – jedenfalls bis jetzt – unerreichbar sind.
In diesem Zusammenhang ist es wichtig, verschiedene Stufen der KI zu unterscheiden. Nach Kaplan und Haenlein [1] lässt sich die Evolution der KI in drei Stufen einteilen:
- künstliche schwache Intelligenz – die Anwendung von KI für spezifische Aufgaben
- künstliche allgemeine Intelligenz – die Anwendung von KI zur autonomen Lösung neuartiger Probleme auf verschiedenen Gebieten
- künstliche Superintelligenz – die Anwendung von KI auf jedes Gebiet, das von wissenschaftlicher Kreativität, sozialen Fähigkeiten und allgemeiner Weisheit profitieren kann
Die meisten der heutigen KI-Lösungen fallen in die erste Kategorie. Demnach könnte auch der Fliehkraftregler, den James Watt 1768 zur Drehzahlregelung an seiner Dampfmaschine nutzte, als KI der ersten Stufe betrachtet werden. Allerdings wurde er nie als solche vermarktet, was auch für Millionen andere Regelungslösungen gilt, die in der Energiewirtschaft, der erdölverarbeitenden und der chemischen Industrie im Einsatz sind.
KI als Lösung
KI-Systeme bestehen typischerweise nicht nur aus einem „Gehirn“, also einem ausgeklügelten Algorithmus, sie müssen auch in der Lage sein, die Welt um sich herum wahrzunehmen und mit ihr zu interagieren. Fähigkeiten wie Sehen, Hören, Sprechen und Bewegung ergänzen dabei das Gehirn und ermöglichen es KI-basierten Systemen, Probleme aus der realen Welt zu lösen – mit anderen Worten Aufgaben, die denen von Prozessleitsystemen sehr ähnlich sind. Während Sensoren Prozessgrößen (abhängige Variablen) wie Druck, Durchfluss, Temperatur usw. messen, errechnen Regler aus diesen Eingaben die bestmöglichen Einstellungen für Aktoren wie Ventile, Dämpfer usw. (unabhängige Variablen), um bestimmte Regelungsziele zu erreichen. In diesem Szenario übernimmt der Regler die Rolle des Gehirns, das algebraische Berechnungen vornimmt und logische Entscheidungen trifft.
Warum jetzt?
Einer der offensichtlichsten Gründe, warum KI zurzeit an Bedeutung gewinnt, ist die exponentielle Zunahme an verfügbarer Rechenleistung. Einige der Einschränkungen, mit denen Datenwissenschaftler in der Vergangenheit zu kämpfen hatten, wie etwa die begrenzte Zahl von Neuronen in künstlichen neuronalen Netzen (KNN), sind Größtenteils verschwunden, sodass das volle Potenzial mehrschichtiger Deep-Learning-Netze ausgeschöpft werden kann. Außerdem kann jeder mit einem Laptop und Zugang zu einer Cloudlösung einen Trainingsalgorithmus ausführen. Dies öffnet den Markt für neue Geschäftsmodelle wie Modelltrainingals Self-Service und Software-as-a-Service (SaaS). Das demokratisiert nicht nur die KI, sondern reduziert auch die Anforderungen an das Engineering von Regelungslösungen.
Die Digitalisierung in der Prozessindustrie begann Ende der 1970er Jahre mit der flächendeckenden Einführung von speicherprogrammierbaren Steuerungen (SPS) und verteilten Leitsystemen (Distributed Control Systems, DCS), die analoge Regelungen ersetzten. Das Hinzufügen neuer Datenpunkte und Regelungsfunktionen wurde mehr zur Programmieraufgabe als eine Frage der Hardwareinstallation und -konfiguration. Dies sorgte für eine signifikante Erhöhung der Flexibilität des Regelungsprozesses bei gleichzeitiger Senkung der Kosten. Doch das Hinzufügen weiterer Funktionen führte zu komplexeren Regelungsstrukturen, die häufig nicht nur schwierig zu verstehen und zu warten waren, sondern auch einen erheblichen Engineering- Aufwand und ein umfassendes verfahrenstechnisches Know-how erforderten. So entstand eine wachsende Nachfrage nach einem schlankeren und transparenteren Regelungsansatz.
Gehobene Prozessregelung
Fortschritte in der Mathematik und Systemtheorie sowie die zunehmende Verfügbarkeit von Rechenleistung haben die Entwicklung gehobenerer Prozessregelungen ermöglicht. Die mathematischen Grundlagen dazu gehen zurück auf die Arbeiten von Rudolf Kalman et al. aus den frühen 1960er Jahren [2]. Während Differentialgleichungen die Dynamik eines physikalischen Systems in einer Art „Reinraum-Szenario“ beschreiben, fügte Kalman Terme für Zustandsstörungen und Messrauschen hinzu – Dinge, die in jeder realen Anwendung unvermeidbar sind. Zudem formulierte er seine Gleichungen direkt in Matrixdarstellung, sodass mehrere Differentialgleichungen mit deren jeweiligen Ein- und Ausgangsgrößen berücksichtigt werden können. Dank dieses Mehrgrößenansatzes (Multiple Input Multiple Output, MIMO) kann nicht nur für einen Aktor zur Zeit, sondern für viele Aktoren gleichzeitig eine optimale Regelungsstrategie berechnet werden.
Darüber hinaus hat sich gezeigt, dass sich Kalmans mathematische Lösung auch nutzen lässt, um in die Zukunft eines Prozesses zu blicken. Im Gegensatz zu einem einfachen Regler, der lediglich den nächsten optimalen Schritt für eine Größe berechnet, war es nun möglich, für mehrere Größen mehrere Schritte in die Zukunft zu sehen. Das Ziel blieb dasselbe: Minimierung des Regelfehlers, also der Differenz zwischen den Soll- und Istwerten. Doch während eine einfache Regelung „auf Sicht“ fährt, erstellt ein vorausschauender Regler einen längerfristigen Handlungsplan.Da jedoch die Dinge häufig nicht wie geplant laufen, wurde klar, dass Regler in der Lage sein müssen, sich mithilfe von Feedback aus dem Prozess an sich verändernde Situationen anzupassen. Dies führte zur Entwicklung der modellprädiktiven Regelung (Model Predictive Control, MPC), die einen optimalen Regelpfad generiert, aber in jeder Iteration nur den ersten Schritt auslöst. Sobald ein Feedback vorliegt, wiederholt die Regelung die Berechnung des optimalen Pfads, bis der gewünschte Betriebspunkt erreicht ist →02.

Obwohl dadurch viele Prozesse erheblich verbessert wurden, gibt es mehrere Bereiche, in denen die Prozessregelung noch immer Einschränkungen unterliegt. Die folgenden Abschnitte beschreiben einige dieser Bereiche und zeigen, wie KI dazu beitragen kann, die verbleibenden Einschränkungen zu überwinden.
Echtzeit-Feedback
Wie oben beschrieben, benötigen Regler Rückmeldungen vom geregelten Prozess, um ihre volle Leistung zu entfalten. Dieses Problem verstärkt sich, je länger die Verzögerung zwischen Regeleingriff und Feedback ausfällt. Insbesondere Daten mit großenZeitabständen zum eigentlichen Prozess können problematisch sein. Dies ist typischerweise bei Labordaten für Produkteigenschaften wie Viskosität oder Flammpunkt der Fall, die sich nicht kontinuierlich oder in Echtzeit messen lassen. Hier sind Anpassungen am Prozess erst möglich, wenn die Ergebnisse aus dem Labor vorliegen, was aufgrund der zwangsläufigen Verzögerung die Produktqualität beeinträchtigen kann.
Eine Möglichkeit, dies zu umgehen, besteht darin, die Werte der Produkteigenschaften in Echtzeit mithilfe von ML-Modellen wie künstlichen neuronalen Netzen (KNN) zu schätzen. Dabei lässt sich die Genauigkeit der Modelle mit jeder neuen Labormessung kontinuierlich verbessern. Die vorhergesagten Eigenschaften können ohne Verzögerung vom Regelalgorithmus zur Anpassung des Prozesses genutzt werden. In dieser Konfiguration arbeiten herkömmliche und KI-basierte Regelalgorithmen Hand in Hand, um die gewünschten Produktionsziele zu erreichen und einzuhalten. Das Konzept lässt sich auch auf Prozesse mit langen Totzeiten oderProzesse mit Sensoren anwenden, die sich regelmäßig neu kalibrieren müssen und somit nicht durchgängig verfügbar sind. →03 beschreibt eine praktische Anwendung dieser Konzepte in einem System zur Emissionsreduktion.
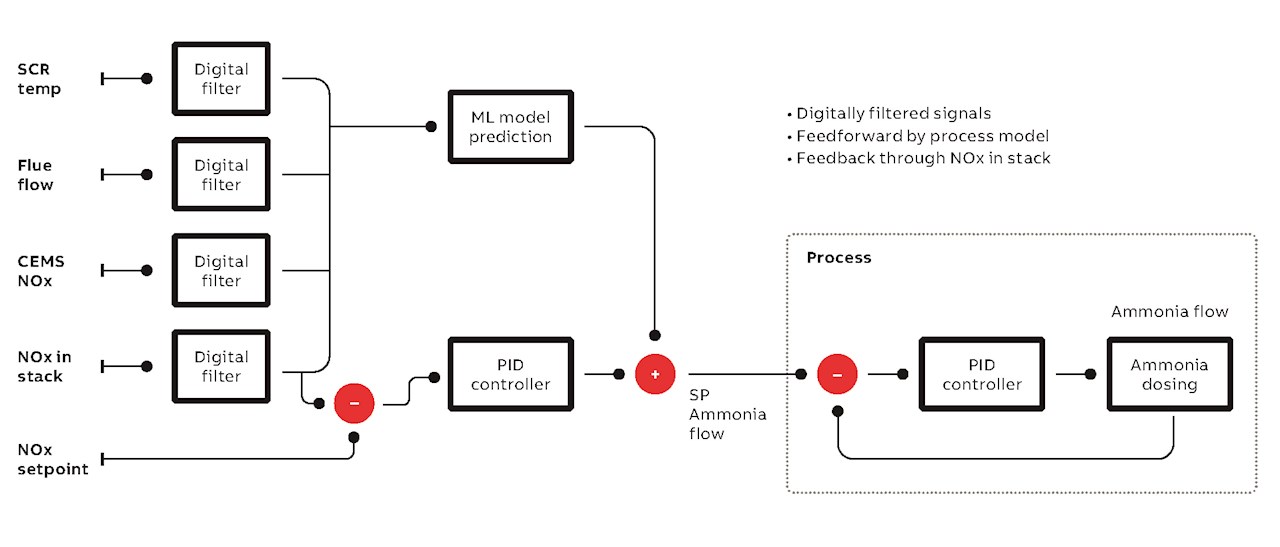
Anpassung an Nichtlinearitäten
Wie die meisten Systeme in der realen Welt sind auch industrielle Prozesse häufig nicht linear. Dies führt zu einer systemischen Diskrepanz zwischen dem realen Prozess und dem linearen Prozessmodell. Bei kurzen Zeithorizonten und geringen Prozessänderungen mag der daraus resultierende Fehler vernachlässigbar sein, doch im größeren Maßstab kann dies die Regelperformance beeinträchtigen. Auch wenn einige Nichtlinearitäten durch Umwandlung der entsprechenden Prozessdaten –zum Beispiel durch Linearisierung der Kennlinie eines Regelventils – ausgeglichen werden können, ist die Linearisierung nicht immer perfekt und kann sehr aufwendig sein, wenn viele Prozessgrößen beteiligt sind.
KI-Verfahren hingegen können sehr gut mit Nichtlinearitäten umgehen. So sind ML-Modelle grundsätzlich in der Lage, sich an jedes nichtlineare Verhalten anzupassen. Auch wenn die meisten MPC-Implementierungen einen linearen Modellierungsansatz nutzen, beinhaltet das Konzept selbst keine Vorgaben im Hinblick auf die Art des Prozessmodells oder seine Linearität. Somit können auch nichtlineare, mit ML-Algorithmen trainierte Modelle zur Reduzierung von Modellierungsfehlern verwendet werden. Dies führt zu einer präziseren Regelung und verhindert, dass sich der Regler in geringfügigen Optimierungen verfängt.
Identifizierung des richtigen Prozessverhaltens
Das Herzstück eines jeden gehobenen Prozessregelungssystems bildet ein Prozessmodell. Doch die Identifizierung der Dynamiken eines physikalischen Systems ist aufwendig und erfordert viel Fachwissen und Erfahrung.

Traditionell gibt es zwei Ansätze beim Model-design: ein sogenanntes physikalisch motiviertes Modell (First-Principle-Modell), das auf dem Aufbau, der Mechanik und der zugrunde liegenden Physik eines Systems basiert, und ein sogenanntes empirisches Modell,das auf Beobachtungen der Systemreaktionen auf Stimuli basiert, die zum Beispiel durch Sprungantwort-Experimente ermittelt werden.
Beide Ansätze können äußerst komplex, aufwendig und – bedingt durch die Natur des Prozesses – manchmal nicht umsetzbar sein. In vielen Fällen kann dies jedoch umgangen werden, wenn geeignete historische Prozessdaten zur Verfügung stehen. Im normalen Anlagenbetrieb werden regelmäßig Sollwerte verändert, und es treten ständig Störungen auf, die Reaktionen im Prozess auslösenund somit sein dynamisches Verhalten aufzeigen. Diese „Fußabdrücke“ können von ML-Algorithmen zur Erstellung genauer Modelle genutzt werden →04. Dazu müssen die Daten repräsentativ sein und dürfen somit nicht zufällig gewählt sein. Außergewöhnliches Prozessverhalten oder Zeiträume mit fehlenden Daten müssen zum Beispiel entfernt werden. Dies manuell durchzuführen, wäre aufwendig, aber für einen Algorithmus eine perfekte Aufgabe. Maschinelle Lernverfahren sind für das Selektieren, Segmentieren und Gruppieren großer Datenmengen ausgelegt →05.

Plattformlösung
Im Laufe der Jahre hat ABB eine Reihe von Regelungs- und Optimierungslösungen entwickelt, die nicht nur die neuesten technischen Entwicklungen auf diesem Gebiet widerspiegeln, sondern häufig auch anführen. Die breite Palette der ABB-Lösungen reicht von der First-Principle-Modellierung über die Überwachung von PID-Regelkreisen (Proportional-Integral-Differential) und die modellprädiktive Regelung bis hin zur dynamischen Optimierung. Dank entsprechender Hardware und maschineller Lernalgorithmen ist es nun möglich, dieses Angebot um die Vorzüge und Möglichkeiten der künstlichen Intelligenz zu erweitern.Vor diesem Hintergrund hat ABB die Plattform ABB Ability™ PlantInsight entwickelt, die das Potenzial von ML-Algorithmen vollumfänglich nutzt. Die webbasierte Anwendung erlaubt die Ausführung verschiedener ML-Algorithmen zur Vorhersage, Segmentierung und Erkennung spezifischer Muster in großen
Mengen von Prozessdaten. Das modulare Konzept unterstützt dabei die einfache Integration proprietärer Python-Skripts zusätzlich zu vorhandenen Skripts.
Unterm Strich kann man sagen, dass sich durch die Verknüpfung von Regelungstechnik mit künstlicher Intelligenz erhebliche Verbesserungen im Hinblick auf die Regelung industrieller Prozesse erzielen lassen. Tatsächlich werden beide Welten mit zunehmender Verbreitung solcher Hybridlösungen weiter zusammenwachsen – was nur natürlich scheint, da beide auf denselben theoretischen Grundlagen basieren. Der kontinuierliche Fortschritt im Zuge dieses Prozesses ebnet den Weg zu den vollständig autonomen Produktionsanlagen von morgen.
References
[1] Andreas Kaplan, Michael Haenlein, “Siri-Siri in my hand, who is the fairest in the Land?” in Business Horizons, vol. 62, no.1, 2019, pp. 15 – 25.
[2] Kalman, R. E. (1960). “A New Approach to Linear Filtering and Prediction Problems.” Journal of Basic Engineering. 82, pp. 35 – 45.