
Ugur Aydin, ABB Motion Services Helsinki, Finland, ugur.aydin@fi.abb.com
Laut einer ABB-Umfrage unter 3.215 Unternehmen [1] liegen die typischen Kosten aufgrund ungeplanter Stillstände in Industriebetrieben bei rund 125.000 USD pro Stunde. In 69 Prozent der Anlagen kommt es mindestens einmal im Monat zu ungeplanten Stillständen. Zweifelsohne spielen Betriebsmittel wie Elektromotoren für den reibungslosen Betrieb in vielen Industrien eine entscheidende Rolle – und Zuverlässigkeit ist der Schlüssel, wenn es darum geht, Ausfälle und die negativen finanziellen Auswirkungen von Stillständen zu minimieren.
Doch trotz der immensen Verbreitung von Elektromotoren – weltweit sind über 300 Millionen Einheiten in Betrieb [2] – ist die Gewährleistung ihrer Zuverlässigkeit eine ständige Herausforderung.
Eine Zustandsüberwachung, die Betriebsdaten von Motoren nutzt, um mithilfe fortschrittlicher Algorithmen Anomalien zu erkennen, könnte dabei helfen, ungeplante Stillstände zu verhindern, indem sie den Betreiber vor sich entwickelnden Problemen warnt, bevor es zu Ausfällen kommt.
Herausforderungen der Anomalieerkennung
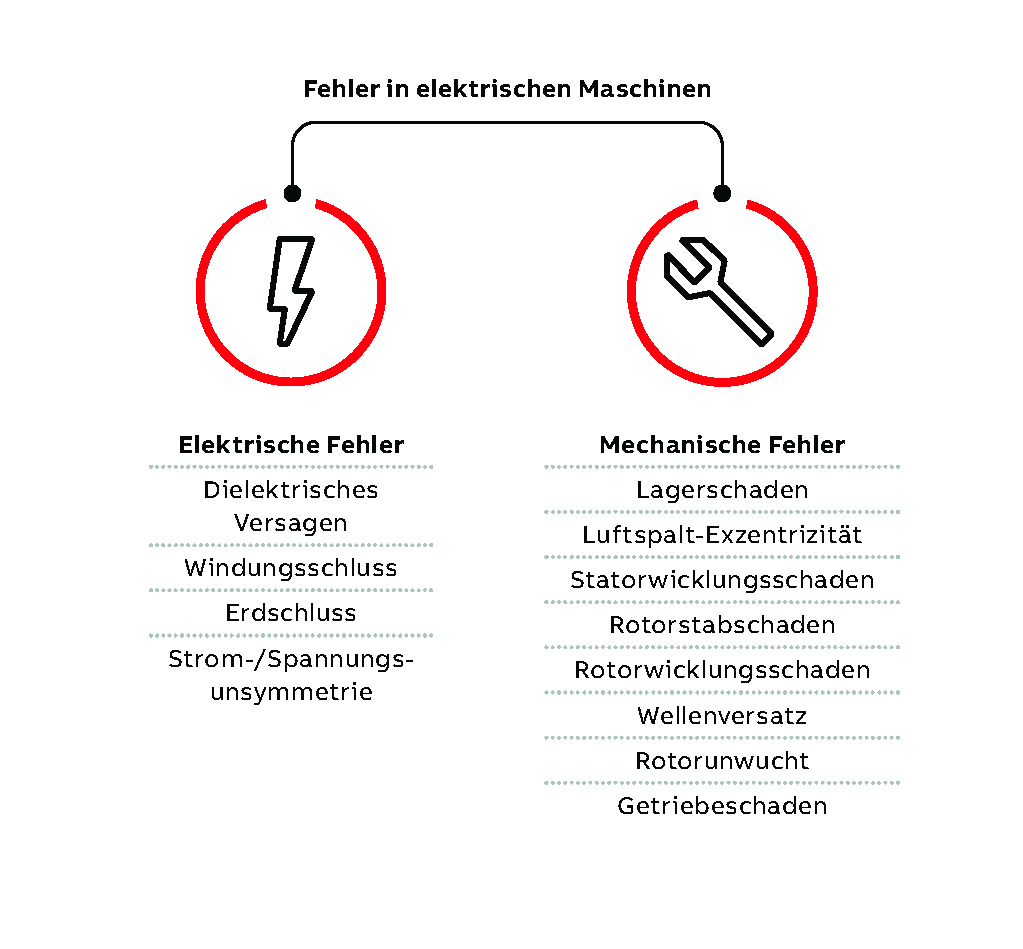
Die möglichen Fehlerarten bei elektrischen Maschinen lassen sich in zwei Hauptkategorien einteilen: elektrische und mechanische Fehler. Die häufigsten elektrischen und mechanischen Fehler sind in →01 aufgeführt. Die Fehler unterscheiden sich in der zugrunde liegenden Physik, und dank fortschrittlicher Signalverarbeitung lassen sich die Symptome in den Vibrationen, im Streufluss, in den Geräuschen und im Stromverlauf eines Motors erkennen [3]. So können mechanische Fehler zum Beispiel anhand bestimmter Oberschwingungen in den Vibrationen des Motors erkannt werden. Solche Oberschwingungen lassen sich durch eine schnelle Fourier-Transformation (FFT) der gemessenen Vibrationssignale aufdecken. Zudem kann eine Wavelet- und Envelope-Analyse der Vibrationen verwendet werden, um verschiedene Fehler mit geringem Eingriff sichtbar zu machen [4]. Früher erfolgte die Überwachung dieser Oberschwingungen manuell oder durch Setzen einfacher Schwellenwerte für die Amplituden. Diese Verfahren sind aufgrund der Anzahl der zu überwachenden Betriebsmittel, des Fehlens universeller Schwellenwerte und des Einflusses von Faktoren wie Maschineneigenschaften, Betriebsdrehzahl und Last jedoch weder effektiv noch praktikabel.
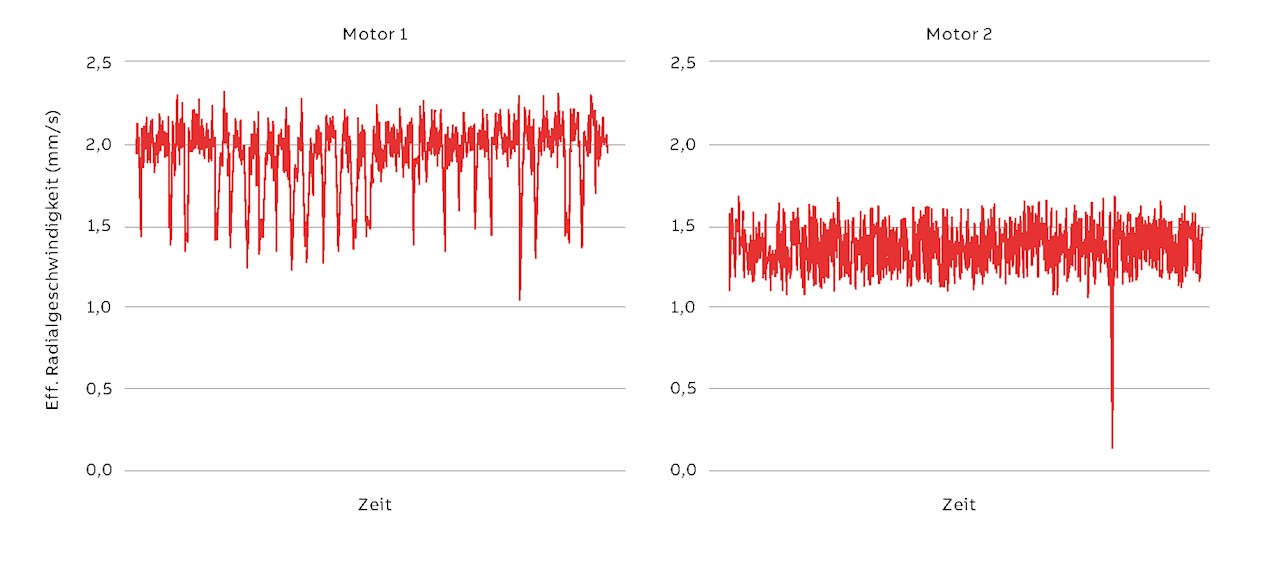
Dank der Fortschritte im Bereich der künstlichen Intelligenz (KI) konnten diese Aspekte in den vergangenen Jahren teilweise gelöst werden. Laut der vorhandenen Literatur eignen sich zum Beispiel Verfahren zum überwachten maschinellen Lernen (ML) zur wirksamen Erkennung und Klassifizierung von Fehlern bei elektrischen Maschinen [5]. Allerdings sind dazu kategorisierte („gelabelte“) Daten der untersuchten Maschinen erforderlich, da sich Modelle, die für eine Maschine entwickelt wurden, möglicherweise nicht für Maschinen mit anderen Größen, Anwendungen oder Betriebsbedingungen verallgemeinern lassen. Nehmen wir zum Beispiel die Messung radialer Vibrationssignale von zwei identischen, fehlerfreien Motoren, die mit unterschiedlichen Lasten verbunden sind →02. Obwohl die Motoren mit ihrer Bemessungsleistung und -drehzahl laufen, unterscheiden sich die Vibrationsmuster deutlich voneinander. Daher würden Modelle, die mit Vibrationsmustern von Motor 1 trainiert wurden, höchstwahrscheinlich falsche Vorhersagen für Motor 2 liefern.
Eine Möglichkeit, dieses Problem zu lösen, besteht darin, mehr Labels von verschiedenen Maschinen zu erfassen und zusätzliche Fehlerfälle zu untersuchen, um größere oder mehrere Modelle zu trainieren. Doch diese Vorgehensweise ist unpraktikabel, teuer und zeitaufwändig. Alternativ könnten unüberwachte Verfahren zur Erkennung von Anomalien aufgrund eines sich verschlechternden Maschinenzustands genutzt werden, da hierbei keine gelabelten Daten zum Training des Modells erforderlich sind.
Dennoch ist das Training eines einzigen generalisierbaren, unüberwachten Anomaliedetektors extrem schwierig, wenn eine ganze Flotte von Motoren überwacht werden soll, was häufig der Fall ist. Hier kommen Faktoren wie Motordesign, Größe, Montageart, momentanes Drehmoment und momentane Drehzahl ins Spiel, die die gemessenen Muster der Motorvibrationen und der magnetischen Flussdichte beeinflussen. Dies kann durch die Verwendung dedizierter unüberwachter Modelle für jeden Motor umgangen werden – und das ist auch der Ansatz, den ABB gewählt hat.
Dabei galt es, zwei entscheidende Kriterien zu berücksichtigen: Erstens sollte – um eine Vielzahl verschiedener Motoren überwachen zu können – anstelle der rechenintensiven DNN-Methode (Deep Neural Network) ein tradition-elles, schlankes ML-Modell gewählt werden, das die Performance nicht beeinträchtigt. Zweitens sollte die richtige Infrastruktur vorhanden sein, um die Bereitstellung und Pflege von Modellen für eine große Anzahl von Motoren zu unterstützen.
Unter Berücksichtigung dieser Kriterien haben die Datenwissenschaftler von ABB eine hocheffektive und skalierbare Lösung zur automatisierten Fehlererkennung für Motoren entwickelt. Diese beinhaltet sowohl eine mustererkennungsbasierte Detektion sich schnell entwickelnder schwerwiegender Fehler als auch einen unüberwachten maschinellen Lernansatz (ML) zur Identifizierung von Fehlern in einem frühen Stadium. Schwerpunkt dieses Beitrags ist das ML-basierte Verfahren.
Entwicklung einer unüberwachten Anomalie-erkennung für Elektromotoren
Die Komplexität, die mit der Entwicklung zuverlässiger, reproduzierbarer und skalierbarer ML-Lösungen verbunden ist, erschreckt viele Unternehmen und hält sie davon ab, das Potenzial dieser Lösungen in realen Anwendungen zu nutzen [6,7]. Um diese Herausforderungen zu bewältigen, griff ABB bei der Entwicklung der Anomaliedetektor-Lösung auf die Best Practices der Disziplin Machine Learning Operations (MLOps) zurück →03.
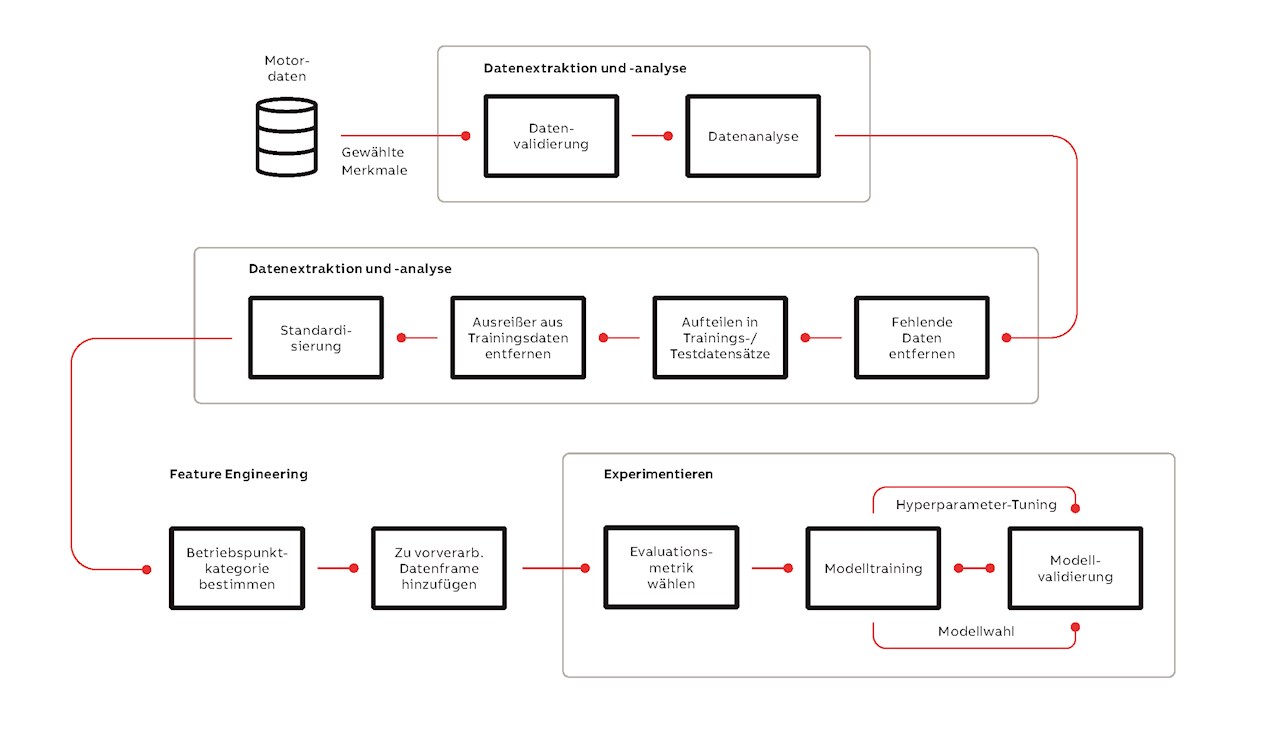
Auch wenn zum Training des unüberwachten Modells keine gelabelten Daten erforderlich sind, hat ABB Daten von verschiedenen Motoren mit bekannten fehlerfreien und fehlerbehafteten Zeiträumen erfasst, um die Validierung des Modells, das Hyperparameter-Tuning und die Modellwahl zu unterstützen. Ist das Modell gewählt, benötigt es lediglich ungelabelte Dateien zum Training. Analysen der gelabelten Daten ergaben eine starke Unausgewogenheit der Daten, wobei die „fehlerhafte“ Klasse deutlich in der Minderheit war. Alle Fehler in den untersuchten Fällen lassen sich mithilfe von Vibrationsmessungen wirksam erkennen.
Zunächst wurden die Daten vorverarbeitet, wobei fehlende Werte entfernt, Trainings- und Testda-tensätze definiert, Ausreißer aus den Trainingsdaten entfernt und die Daten standardisiert wur- den. Anschließend wurden beim sogenannten Feature Engineering neue Merkmale aus vorhandenen Daten erstellt, um die Performance der Anomalieerkennung zu verbessern. Dabei wurde ein kategorisches Merkmal generiert, um die gemessenen Datenpunkte nach ihrer Abweichung von der Bemessungsdrehzahl bzw. dem Bemessungsschlupf zu einzuteilen. Für drehzahlgeregelte Motoren wurde die Drehzahl, für direkt netzbetriebene Motoren der Schlupf verwendet. Das neue Merkmal hilft bei der effektiven Be-trachtung des Betriebsverhaltens des Motors.
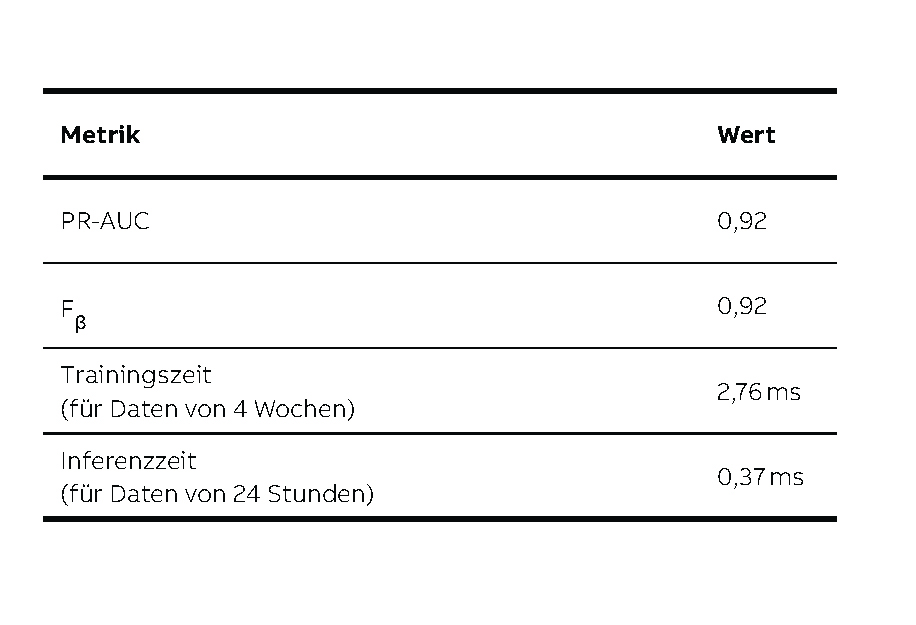
Der letzte Schritt beinhaltete die Durchführung von Versuchen zur Modellwahl. Dazu wurde das Modell mit einer zuvor festgelegten anfänglichen Anzahl fehlerfreier Datenpunkte trainiert. Als Evaluationsmetriken für ein solches binäres Klassifizierungsproblem mit stark unausgewogenen Daten wurden PR -AUC (Precision-Recall Area Under Curve) und Fβ-Score (mit β = 0,5) herangezogen, um der Präzision mehr Gewicht zu verleihen und falsch positive Ergebnisse zu reduzieren. PR -AUC wurde für das Hyperparameter-Tuning des Modells und Fβ-Score zur Optimierung der Anomalie-Schwellenwerte verwendet. Zusätzlich zu den Evaluationsmetriken wurde eine Nebenbedingung zur Berücksichtigung des Rechenaufwands definiert. Untersucht wurden die Algorithmen One-Class Support Vector Machines (OCSVM), Isolation Forest, Minimum Covariance Determinant, Robust Random Cut Forest und Local Outlier Factor, wobei OCSVM im Hinblick auf die Evaluationsmetriken und den Rechenaufwand am besten abschnitt →04.
Modellbereitstellung
Zur Bereitstellung des Modells wurden sämtliche Entwicklungsschritte zu einer Pipeline verknüpft. Im Hinblick auf die Infrastruktur besteht eine der größten Herausforderungen darin, eine Infrastruktur zu konzipieren, die in der Lage ist, Tausende von Modellen in einer akzeptablen Zeit zu trainieren und zu unterstützen. Dazu hat ABB auf die parallele Verarbeitungsfunktionalität von Microsoft Azure Machine Learning Studio zurückgegriffen, bei der die Auftragsausführung auf parallele Rechencluster oder -knoten verteilt werden kann [8]. Dies lässt sich wiederum durch Erhöhung der Cluster- oder Knotenanzahl skalieren, was allerdings seinen Preis hat. Dank des geringen Rechenaufwands des OCSVM-Algorithmus wurden nur erschwingliche CPU-Cluster verwendet.
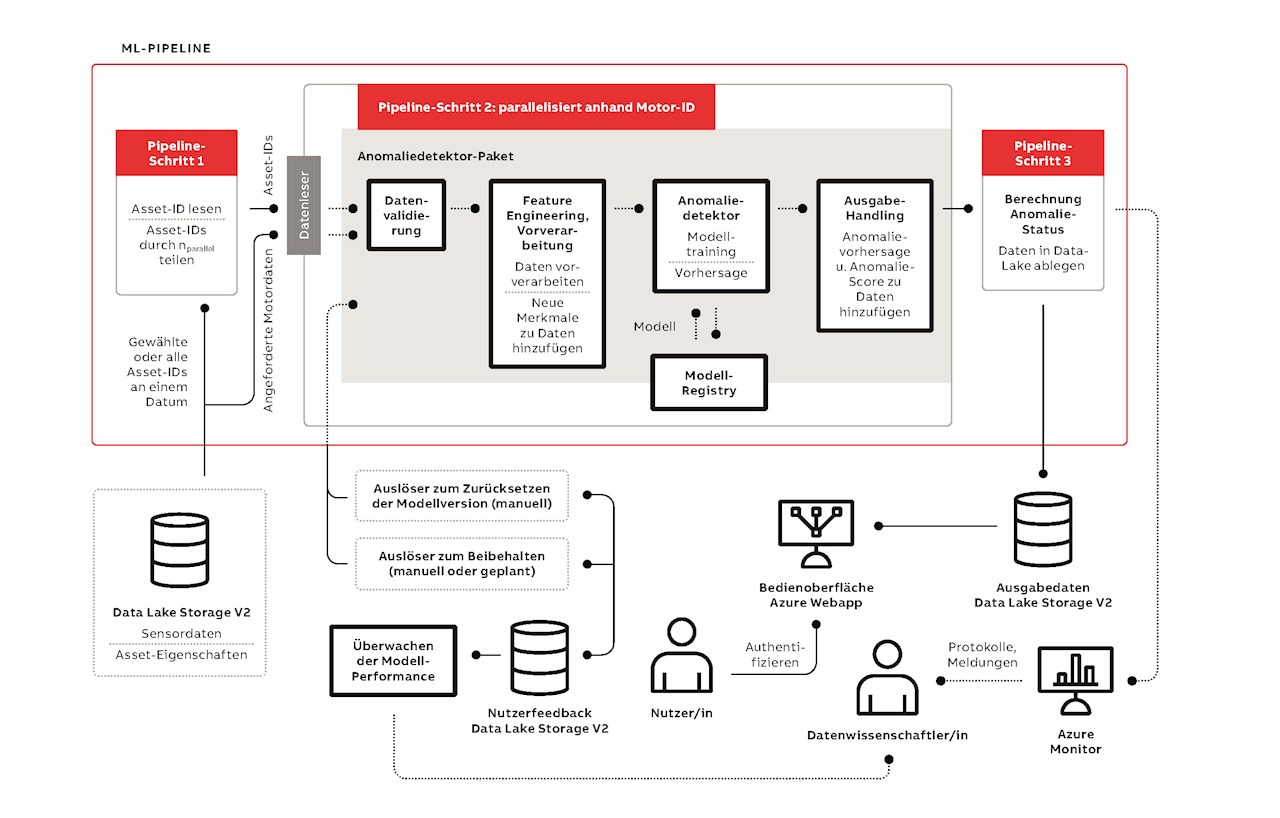
Die Pipeline umfasst drei Hauptschritte: Parallelisierung, Anomalieerkennung und Nachverarbeitung. Im Parallelisierungsschritt werden die verfügbaren Daten auf ein bestimmtes Datum hin überprüft, die entsprechenden Asset-IDs gelesen und die Aufteilung für die parallele Verarbeitung vorgenommen. Der Anomalieerkennungsschritt bildet das Kernstück der Lösung und umfasst die Datenextraktion, Validierung, Vorverarbeitung, das Feature Engineering, Modelltraining und die Vorhersage. Das Modelltraining erfolgt automatisch mithilfe der ersten vorgegebenen Menge von Motordaten, von denen angenommen wird, dass sie einen fehlerfreien Betrieb widerspiegeln. Die trainierten Modelle werden versioniert und in der Mod ell-Registry zur Verwendung in zukünftigen Vorhersagen registriert.
Im Nachverarbeitungsschritt wird der Bedeutungsfaktor für Anomalien berechnet, um eine entsprechende Benachrichtigung der Nutzer zu ermöglichen. Abschließend werden die Ergebnisse zur weiteren Analyse auf einer Bedienoberfläche dargestellt.
Ein wichtiger Aspekt der Pipeline ist das automatisierte Nachtrainieren der Modelle, das regelmäßig nach Plan erfolgt. Die Auswahl der Trainingsdaten zur Aktualisierung eines Modells für einen bestimmten Motor erfolgt durch zufällige Entnahme von Stichproben aus den vom Modell bestimmten fehlerfreien historischen Datenpunkten, wobei den neuesten Datenpunkten ein stärkeres Gewicht gegeben wird. Ein solches Nachtrainieren hilft den Modellen, Umwelteinflüsse zu berücksichtigen, die zum Beispiel durch saisonale Temperaturschwankungen, Veränderungen der Luftfeuchtigkeit und die Installation neuer Ausrüstung in der Nähe verursacht werden und die Vibrationsmessungen beeinflussen könnten.
Bedienoberfläche
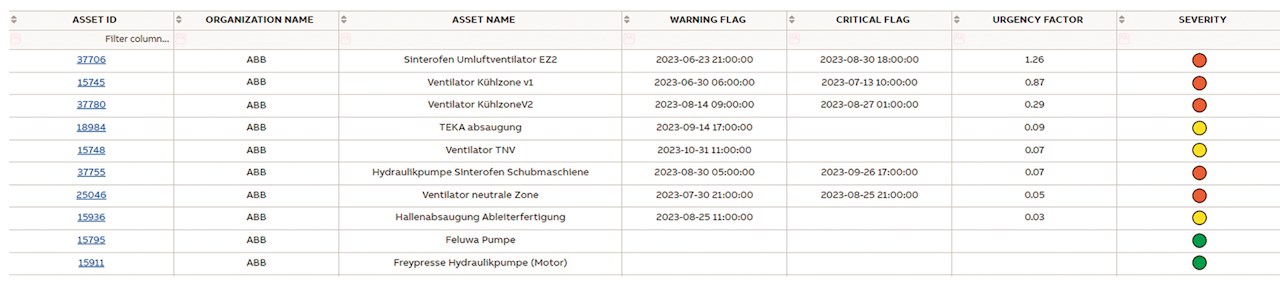
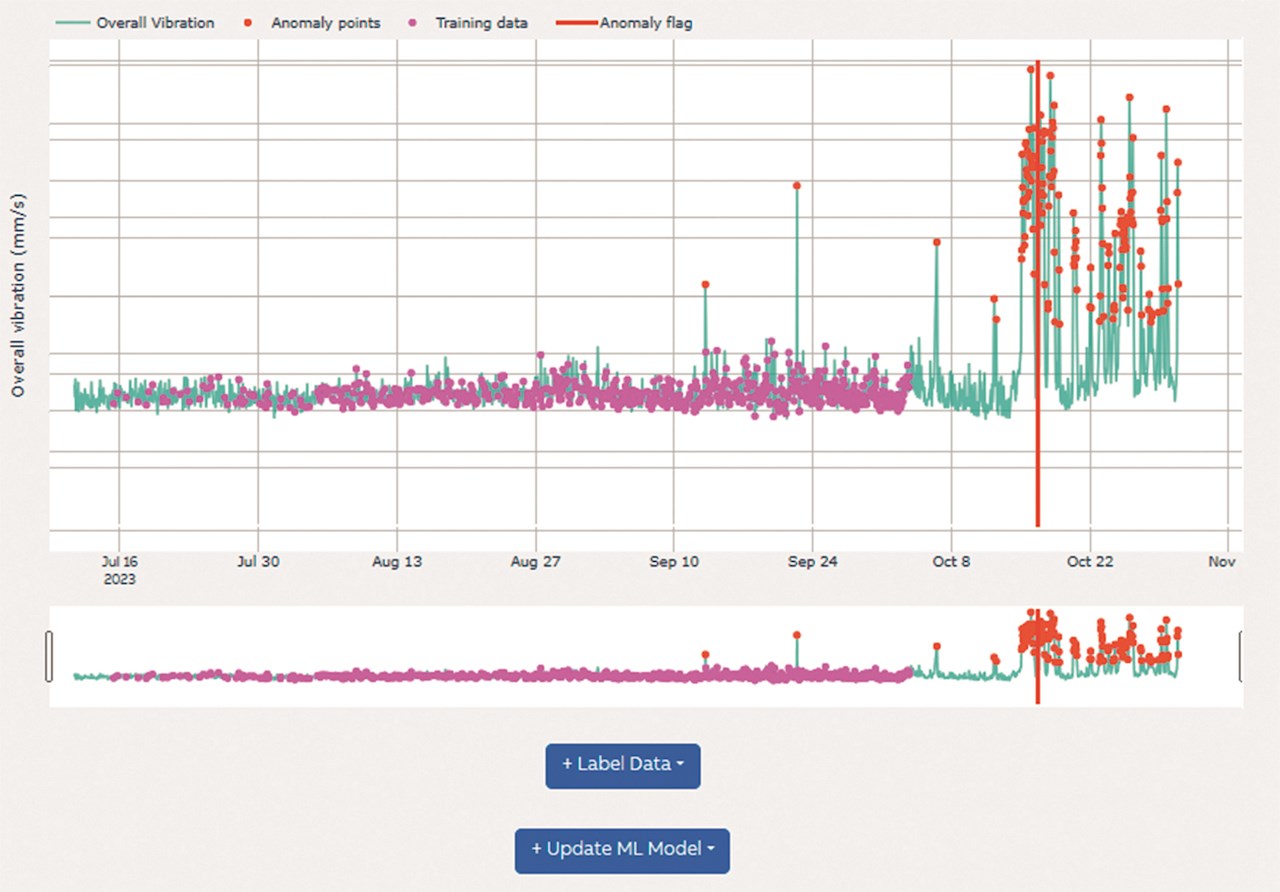
Zu den umfangreichen Funktionen der Bedienoberfläche für die Pipeline gehört eine tabellarische Zusammenfassung der Informationen zu den Motoren mit erkannten Anomalien →06. Für Nutzer wie Datenanalysten stehen interaktive Filter zur Verfügung, mit denen sie auf die Daten zuzugreifen können, die sie benötigen. Darüber hinaus gibt es ein Liniendiagramm, das die maximale effektive Vibration entlang der drei Achsen darstellt und mögliche Anomalien aufzeigt →07.
Zudem bietet die Bedienoberfläche eine Funktion, mit der Daten annotiert werden können, um dem Modell Feedback zu geben. Diese Annotationen spielen eine entscheidende Rolle bei der Überwachung der Modellperformance. Wenn mehr Labels erfasst werden, lässt sich das Potenzial überwachter Verfahren nutzen. Außerdem haben Nutzer/innen die Möglichkeit, ein Nachtraining des Modells zu veranlassen, um eine neue Version zu erhalten. Diese Kontrolle über das Modelltraining ist sehr nützlich. Wird zum Beispiel ein Motor repariert oder ersetzt, können sich die Vibrationseigenschaften im Vergleich zu vorher komplett ändern. Das Modell kann auch auf eine vorherige Version zurückgesetzt werden, wenn die Performance damit besser war.
Fallbeispiel
Die Anomalieerkennungsfunktion von ABB hat ihre Wirksamkeit in einer speziellen Industrieanwendung unter Beweis gestellt. Dabei meldete das System eine frühe Anomalie an einem Motor, der einen Lüfter über einen Riemen antreibt. Eine genauere Analyse der Vibrationsrohdaten durch einen ABB-Experten mithilfe fortschrittlicher Signalverarbeitungstools lieferte Hinweise auf erhöhte Oberschwingungen in Verbindung mit der angetriebenen Ausrüstung. Bei einer physischen Überprüfung zeigte sich, dass das Lager des angetriebenen Lüfters und der Antriebriemen beschädigt waren.
Das Fallbeispiel zeigt, dass der Anomaliedetektor in der Lage ist, sogar ein Problem erfolgreich zu erkennen, dessen Ursprung nicht im Motor selbst, sondern in der Anwendung liegt. Dies beweist, dass der ML-basierte Anomaliedetektor bereit ist, Anwendern in Zukunft dabei zu helfen, Fehler frühzeitig zu beseitigen und ungeplante Stillstände zu verhindern.
Danksagung
Der Autor bedankt sich bei den Datenwissenschaftlern Ignacio Rodriguez Burgos und Dominik Suszalski sowie dem Softwareentwickler Piotr Drabik vom ABB Motion Services Analytics Team, die maßgeblich zur Entwicklung der KI-basierten Erkennungsfunktion beigetragen haben. Weiterer Dank gilt Matthew Gladden für das sorgfältige Lektorieren und Redigieren des Artikels.
Literaturhinweise
[1] ABB, “Value of Reliability: ABB Survey Report” ABB press release website, 2023, Available: https://search.abb.com/library/Download.aspx?DocumentID=9AKK108468A6878&LanguageCode=en&DocumentPartId=&Action-=Launch [Accessed: Dec. 11, 2023.]
[2] ABB, “ABB Inverter Duty Motors”, ABB Technology website, 2023, Available: https://global.abb/group/en/technology/did-you-know/inverter-duty-motors [Accessed: Dec. 11, 2023.]
[3] Gundewar, et al., “Condition Monitoring and Fault Diagnosis of Induction Motor”, Journal of Vibration Engineering & Technologies, vol. 9(4), 2021, pp. 643 – 674, Available: https://doi.org/10.1007/s42417-020-00253-y
[4] Tse, P. W., Peng, Y. H., & Yam, R. “Wavelet Analysis and Envelope Detection for Rolling Element Bearing Fault Diagnosis—Their Effectiveness and Flexibilities”, Journal of Vibration and Acoustics, vol. 123(3), 2001, pp. 303 – 310, Available: https://doi.org/10.1115/1.1379745
[5] Surucu O., et al., “Condition Monitoring using Machine Learning: A Review of Theory, Applications, and Recent Advances”, Expert Systems with Applications, Vol 221, 2023, pp. 119738, Available: https://doi.org/10.1016/j.eswa.2023.119738, [Accessed Nov 21, 2023.].
[6] Baier, L., et al., “Challenges in the Deployment and Operation of Machine Learning in Practice”, 27th European Conference on Information Systems (ECIS), Stockholm & Uppsala, Sweden, June 8 – 14, 2019.
[7] Paleyes, A., et al., “Challenges in Deploying Machine Learning: A Survey of Case Studies”, ACM Computing Surveys, vol. 55(6), 2023 pp. 1 – 29, Available: https://doi.org/10.1145/3533378
[8] Microsoft web site, “What is Azure Machine Learning?”, 2024, Available: https://learn.microsoft.com/en-us/azure/machine-learning/overview-what-is-azure-machine-learning?view=azureml-api-2 [Accessed 29 Feb. 2024.]